Installation and set-up
Data
- I keep getting an “Error: Out of range for file…”. What does that mean?
- How do I specify missing data?
- I have data formatted for another program and it doesn’t have spaces between the responses. Can flexMIRT® analyze this data as is?
- Can flexMIRT® import data from other programs (e.g., SAS, SPSS, Excel)?
- How do I get flexMIRT® to analyze data only if the responses are list-wise present?
- I have an extremely large dataset, with a large number of respondents, items, and factors that I would like to estimate. Are there limits to the size of the dataset/model that flexMIRT® is able to handle?
Capabilities and Technical Information
- Other programs provide trace line plots and TIF curves for me. Will flexMIRT® make plots for me?
- Am I able to use flexMIRT® for exploratory factor analysis (EFA)?
- I have lots of different datasets that I need to analyze and want to run flexMIRT® through the command prompt. Is that possible?
- flexMIRT® tells me that I have an error on line XX. Is there a way to get flexMIRT® to show the line numbers in the syntax editor?
- flexMIRT® just stops in the middle of an analysis, producing no output, only reporting “Finished in XX ms.” What’s wrong?
- I’m using maximum likelihood (ML) scoring with a multidimensional model and I’m getting undefined values and/or unreasonable estimates. Is this a bug?
- My model runs but it’s extremely slow. Is something wrong? How can I speed it up?
- I’ve specified that flexMIRT® may use more than one processor in the
<Options>section but my estimation does not seem to be running any faster. What’s the problem? - I’m using supplemented EM standard errors but the SEM cycles finish very quickly without converging? The point estimates of my items look OK. How do I fix this?
- I have item parameters from a different program that I would like to use to score data in flexMIRT®. How do I transform the values I have into the values flexMIRT® requires for the -prm file?
- If flexMIRT® is only estimating the intercepts, where are the SEs for the difficulty/b-parameters coming from when flexMIRT® is reporting unidimensional models?
Output
- What do the first- and second-order tests in the Convergence and Numerical Stability section of the output test?
- Is it possible to get the original nominal model parameterizations saved to the -PRM file?
- I fit a multidimensional model and flexMIRT® is only printing the intercept values (c parameters). I would like thresholds (bs) instead. Can I make flexMIRT® print those?
- Is it possible to obtain normal metric parameter estimates from flexMIRT®?
- I’m fitting a multi-level model and have specified that flexMIRT® should print additional GOF indices via
GOF = Extended;in the<Options>section. Even with that command, I’m still only getting the basic indices. Why? - Can I estimate the percent of variance attributable to each level in multilevel IRT like I can in multilevel linear regression?
Other
Installation and set-up
I need to register flexMIRT® on a computer that is not connected to the internet. How do I do that?
To register flexMIRT® on a computer without internet access, please contact us by email at support@vpgcentral.com or submit a request via our support portal.
Data
I keep getting an “Error: Out of range for file…”. What does that mean?
You most likely have non-zero based data. flexMIRT® requires that responses start at 0 and go up from there. If you are working with graded data with responses 1,2,3,4, this needs to be recoded in the <Groups> section using something like Code(items) = (1,2,3,4), (0,1,2,3); where “items” are the items that have the 1 – 4 original scoring.
The other likely source of this error is there is an unexpected value present in the dataset. For instance, if you have said there are 2 categories for all item, flexMIRT® expects 0s and 1s. If there are, for example, respondents who have a value of 2 on an item, this would also cause the “Out of Range” error.
How do I specify missing data?
The default value for missing data is -9, although this may be changed to any other numeric value using a statement in the <Groups> section (e.g., Missing = 99;). Currently, flexMIRT® is only able to handle numeric values for missing data, so a period (.) or a blank space ( ) would not be recognized as missing data and cannot be specified as the missing data value.
I have data formatted for another program and it doesn’t have spaces between the responses. Can flexMIRT® analyze this data as is?
Currently, there is no way to specify the formatting of data strings, which would allow flexMIRT® to interpret the responses correctly. Data files must use space, tab, or comma delimiters between variables and may not contain a variable name header.
Can flexMIRT® import data from other programs (e.g., SAS, SPSS, Excel)?
flexMIRT® does not currently have an import capability. You will need to export your data from the original program in a format appropriate for flexMIRT®.
How do I get flexMIRT® to analyze data only if the responses are list-wise present?
Currently, flexMIRT® does not have options to specify the type of present or desired missingness (list wise, pairwise, etc). However, flexMIRT® uses full-information estimation, so all available data is included in the likelihood. Full information estimation obviates the use of such missingness specifications, as they reduce the number of data points available and result in an unnecessary loss of information.
I have an extremely large dataset, with a large number of respondents, items, and factors that I would like to estimate. Are there limits to the size of the dataset/model that flexMIRT® is able to handle?
There is no practical limit (beyond your computer or operating system’s capabilities) on the number of dimensions one may estimate or the number of items/respondents one may include.
Capabilities and Technical Information
Other programs provide trace line plots and TIF curves for me. Will flexMIRT® make plots for me?
flexMIRT® currently does not have integrated plotting capabilities. However, all the necessary information for such plots is provided in the output and can be easily transferred into a program capable of plotting (e.g., Excel). For unidimensional models, users may include the new-to-flexMIRT® 3.6 statement of SaveICC = Yes; in the <Options> section of their syntax and the necessary values for constructing item characteristic curves/trace line plots will be saved to an output file with the -icc.txt extension
We have also provided R syntax files, located on the Support page under “Plotting Examples,” which will import flexMIRT® parameters and produce basic trace lines plots for unidimensional models with very little user input. Please note that these syntax files are provided without warranty or support.
Am I able to use flexMIRT® for exploratory factor analysis (EFA)?
Introduced in flexMIRT® 3.0, flexMIRT® has an established history of conducting exploratory factor analysis with analytic rotations. Please see the MIRT and/or Alternate Estimation Methods for High-Dimensional and Complex Models chapters of the user’s manual for details.
I have lots of different datasets that I need to analyze and want to run flexMIRT® through the command prompt. Is that possible?
We have updated the flexMIRT® User Manual with an appendix (Appendix B) on how to run flexMIRT® through the command line interface. flexMIRT® 3.6 also has a newly implemented GUI feature to allow for the point-and-click creation and running of batch files, also detailed in Appendix B.
flexMIRT® tells me that I have an error on line XX. Is there a way to get flexMIRT® to show the line numbers in the syntax editor?
The newly updated flexMIRT® 3.6 GUI includes line numbers by default.
In flexMIRT® 3.51, line numbers are not available. However, if you copy your code into a text editor such as Notepad, and have the Status Bar turned on under View, you can find a specific line number that way and then alter your flexMIRT® code as needed.
flexMIRT® just stops in the middle of an analysis, producing no output, only reporting “Finished in XX ms.” What’s wrong?
In our experience assisting users, the most often seen cause is that one or more items do not have observations in specified response categories. For example, flexMIRT® is told that an item has 4 categories and should fit the Graded(4) model but, in the data, there are not observations that have a value of 2. It is impossible for flexMIRT® to estimate an intercept between two categories if one of the categories is not seen in the data. Collapsing/recoding the data so observed response values are sequential and specifying an item model with an appropriate number of categories is one way to resolve the problem.
flexMIRT® running out of available memory can also cause the noted behavior. This is often seen in the calibration or scoring of multidimensional models with the EM algorithm if the quadrature points have not been reduced from the default setting of 49 points spread from -6 to 6. As the number of dimensions increases linearly, the number of quadrature points increases exponentially. With higher dimensional models, the total number of quadrature points (and, therefore, required memory) may become unworkable if the default value is maintained. Details about the Quadrature command, which controls the number and spread of points, are available in Syntax chapter of the User’s Manual.
Another possible cause of such behavior is an unidentified model. For example, a multidimensional model in which all items load on all factors is not identified and unable to be estimated. It is the user’s responsibility to ensure that the specified model is statistically identified. Rules for identification are beyond the scope of software support, but we recommend Cai (2010)’s exploratory item factor analysis article in Psychometrika or Bollen’s (1989) book on latent variable models as possible starting points.
If you have verified that all items have observations in all response categories and your model is identified and tried using reduced quadrature points, please feel free to contact us for further help if the issue remains. Without you active flexMIRT® license code, please send a description of the problem behavior, the code you have written, and the dataset (if possible) by email to support@vpgcentral.com or submit a request via our support portal. We will respond as soon as possible.
I’m using maximum likelihood (ML) scoring with a multidimensional model and I’m getting undefined values and/or unreasonable estimates. Is this a bug?
We strongly recommend against the use of ML scoring with MIRT models. Efforts have been made to make ML scoring as robust as possible, but because ML scoring does not use information from the population distribution, essential statistical information about the population distribution (e.g., factor inter-correlations, means, and variances) is ignored when scoring individual dimensions of MIRT models. Additionally, ML scoring can lead to score information matrices that are not positive definite, making the SEs for some estimates undefined.
My model runs but it’s extremely slow. Is something wrong? How can I speed it up?
Some models are very complex and will require longer run times. If you are working with multidimensional models, you can try increasing the number of processors available to flexMIRT® (default is 1) or decreasing the number of quadrature points provided that the reduced precision of numerical integration does not substantially degrade the estimation quality and stability (default is 49 points over the range -6 to 6). These things can be accomplished, respectively, by using statements such as Processors = 3; and Quadrature = 21, 5.0; for example in the <Options> section of your flexMIRT® syntax.
If you are running a bifactor model, be sure you have specified in the <Groups> section the number of primary dimensions (e.g., Primary = 1;), which will allow flexMIRT® to employ its dimension reduction technique. This should also increase the speed of the run.
Additionally, requesting the computation and printing of the M2 GOF statistic may lead to increased processing time, especially in the case of large numbers of items. The overall limited-information fit indices require the computation and inversion of very large matrices. For instance, with 100 items, there are at least 100*101/2 = 5,050 univariate and bivariate subtables, and consequently the asymptotic covariance matrix of the univariate and bivariate probabilities is 5,050 x 5,050, which has 5050*5051/2 = 12,753,775 elements. The program will try to compute this matrix, regardless of size, but it will take far too long for what is worth when the number of items is large. For timely M2 computations, the practical upper limit for the number of dichotomous items is about 120 and for polytomous items, about 50.
I’ve specified that flexMIRT® may use more than one processor in the <Options> section but my estimation does not seem to be running any faster. What’s the problem?
It is possible that a parallel run (employing more than 1 processor) may end up taking longer, especially if the problem is mostly M-step dominated in complexity. The Bock-Aitkin EM algorithm isn’t easy to parallelize because there is quite a bit of synchronization needed between E and M steps; there is usually a barrier so that processors must wait for all members of the team to finish before proceeding to the next task. This overhead, if it is proportionally larger than the parallel speed-up, can even cause parallelized programs to run slower.
The speed-up achieved by using more than one processor also depends on the size of the problem (in the number of people, items, and dimensions), and how much memory is being consumed.
I’m using supplemented EM standard errors but the SEM cycles finish very quickly without converging? The point estimates of my items look OK. How do I fix this?
In the <Options> section of your syntax, including the command SmartSEM = No; which will allow flexMIRT® to use the full iteration history, may lead to a better window and a converged SEM algorithm. If that fails to solve the problem, if you adjust the E-step tolerance value or M-step tolerance value to something smaller than the default in the <Options> sections (via eTol = ; or mTol = ; respectively), this will also increase the size of the window within which the SEM SEs are expected to converge. Note, however, the non-covergence of the supplemented EM algorithm within the “smart” window often reflects an EM path that is not smooth and is suggestive of model error that should be explored.
I have item parameters from a different program that I would like to use to score data in flexMIRT®. How do I transform the values I have into the values flexMIRT® requires for the -prm file?
The first step is to determine the metric and parameterization of the existing item parameter values. In the -prm file you will construct, flexMIRT® expects, by default, that logistic metric, slope/intercept (rather than slope/threshold) values will be given.
If providing guessing values for the 3PL, the values in the -prm will need to be logit-guessing, not typical g-parameter values. This PDF provides additional details on the parameterization of the 3PL (and GPC) in flexMIRT®.
Due to several questions regarding conversion of the GPC model, this zip file contains details regarding the Nominal model that flexMIRT® uses, a labeled example of a -prm file for GPC items, and an example of the conversions needed to go from more typical GPC parameters to the parameters flexMIRT® expects in the -prm file for scoring.
If flexMIRT® is only estimating the intercepts, where are the SEs for the difficulty/b-parameters coming from when flexMIRT® is reporting unidimensional models?
The multivariate delta method is used to obtain the SEs for the b-parameters. Specifically, consider b as a scalar-valued function of two parameters (a and c), b(a,c) = –c/a, and naming V the submatrix of the covariance matrix for the particular a and c parameters of interest
V =
var(a)
cov(a,c) var(c)
The Jacobian matrix of b(a,c) is 1×2:
J = (db/da db/c) = (c/a^2 -1/a)
The multivariate delta method approximation to threshold b’s error variance is equal to J V J’. All matrices should be evaluated at the MLE.
Output
What do the first- and second-order tests in the Convergence and Numerical Stability section of the output test?
The first order test examines if the gradient has vanished sufficiently for the solution to be a stationary point.
The second order test tests if the information matrix is positive definite, a prerequisite for the solution to be a possible maximum.
By default, flexMIRT® uses the Bock-Aitkin EM algorithm to obtain marginal maximum likelihood estimates. For the second order test, reporting that the solution is a possible maximum simply means that the program reached a statistically desirable solution. The other possible message that may be printed for the outcome of the second-order test is “Solution is not a maximum; caution is advised.” If that message is received, all parameter estimates should be taken a provisional and should not be used as final estimates, for future scoring, etc.
Is it possible to get the original nominal model parameterizations saved to the -PRM file?
Currently there is not an option to save the original parameterization values into the -PRM file, though they are printed in the output. Using the alpha and gamma values saved into the -PRM file and following the formulae in Thissen, Cai, and Bock (2010), specifically the T matrix described in Eq. 3.35 and 3.36 and parameter conversions found in Eqs 3.37 – 3.41, users may obtain the estimates in the original parameterization. Please note that there is an error in Eq. 3.41 in the chapter, which should read:
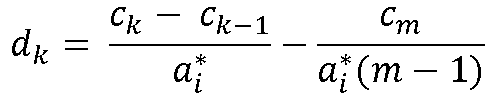
I fit a multidimensional model and flexMIRT® is only printing the intercept values (c parameters). I would like thresholds (bs) instead. Can I make flexMIRT® print those?
As a logistic multidimensional model, threshold parameters are not straight forwardly derived and tend to have far less logical and theoretical basis; for these reasons, flexMIRT® will not print them. However, you can convert the logistic intercepts into approximate Normal metric threshold parameters using the following method:
First, put the slopes on the approximate Normal metric by dividing each by the IRT scaling constant 1.7. Then compute the sum of squares of the rescaled slopes. Add 1.0 to the result and take its square root; this gives you the constant you will need to convert all the intercepts.
To convert the intercepts, first add a minus sign and then divide the intercepts by 1.7 to also make them on the normal metric. Then divide each intercept by the constant found above. You use the same constant for all the intercepts in this item. When you move on to the next item, however, you will need to repeat the process for finding the conversion constant.
For example, if an item was found to have slope parameters of a1 = 1.28 and a2 = 1.67, the conversion constant would be found by sqrt((1.28/1.7)2+(1.67/1.7)2+1) = 1.59.
If the first intercept value was 5.35, the converted threshold parameter may be obtained from first putting the intercept on the Normal metric (-5.35/1.7 = -3.15) and then dividing by the conversion constant (-3.15/ 1.59 ≈ -1.98).
Is it possible to obtain normal metric parameter estimates from flexMIRT®?
If using the 3PL model, the command NormalMetric3PL = Yes; included in the <Options> section results in the printing of normal metric parameters in the output and, if requested, the output -prm file.
If using the Graded model, there is no shortcut keyword available but the Coeff keyword may be used in the <Constraints> section to include a desired scaling constant (e.g., 1.702) into the parameter estimation and reporting. Details for use of the Coeff keyword are available in the Syntax chapter of the user’s manual. Note that the -prm file will include the typical logistic metric values, but parameter values incorporating the requested coefficient are output into the debugging file, which can be requested via SaveDBG = Yes; in the <Options> section.
When using the Coeff keyword, any prior distributions that are specified will be applied to the parameter incorporating the stated coefficient, not the default estimated parameter. For example, if the desired mean of the slope prior distribution was 2.1 in the logistic metric, then a prior statement of Prior, (VarX), slope: normal(1.23, 1.0); would be specified, due to 2.1/1.702 = 1.233.
I’m fitting a multi-level model and have specified that flexMIRT® should print additional GOF indices via GOF = Extended; in the <Options> section. Even with that command, I’m still only getting the basic indices. Why?
The GOF command currently has no effect for multilevel models. Research on model fit testing for multilevel IRT models is a developing area. For now, only the -2 log-likelihood, AIC, and BIC values will be printed.
Can I estimate the percent of variance attributable to each level in multilevel IRT like I can in multilevel linear regression?
It is possible to perform variance decomposition from multilevel IRT models, but currently it must be done by hand, using values from the output. First, you must set up your multilevel model in such a way that allows for the variance decomposition. This entails constraining all item slopes to equality across the Between and Within levels. With the identification constraint that the Within-level variance is 1.0, the Between-level variance can be freely estimated.
Using the variance values for the Between and Within factors from the output of the above model, you may find the variance due to the Between factor as (VarB/W / VarB/W + VarW/in). For example, if the Within factor variance was constrained at 1.0 and the estimated Between variance was 3.14, the variance due to the Between factor would be 3.14 / 3.14 + 1.0 = 0.76 or 76%.
Other
I have a problem that isn’t addressed here. What now?
We are always willing to help with any flexMIRT® issues you are having. Send a description of the problem you are having along with your active flexMIRT® license code, the version of flexMIRT® you are using, the code you have written, and the dataset (if possible) by email to support@vpgcentral.com or submit a request via our support portal. We will respond as soon as possible.